 Image generated with Google Gemini (2026).
Image generated with Google Gemini (2026).
From Reno to BBR
In the fall of 1986, the network between Van Jacobson’s lab and the Berkeley campus a quarter mile away stopped working. Throughput between Lawrence Berkeley Laboratory and the university fell from 32 kilobits per second to 40 bits, nearly a thousandfold[1].
Jacobson went looking for the cause. He realized the senders had no idea when to slow down, so the instant the link filled they kept pushing and strangled it. He gave TCP a way to feel the congestion and back off, and the link came back to life. That was congestion collapse, and the fix he and Michael Karels built is the reason the internet kept working as it grew[1].
That fix still runs on every device you’re holding right now.
What Is Congestion Control?
Congestion control is the algorithm a TCP sender runs to guess its own speed. The network never tells it the right rate. There is no spare-bandwidth dial and no slow-down message. The sender is blind and has to probe by pushing until something fails[1].
In 1988, Jacobson published the first answer that worked[2]. Send a little, ramp up fast, and the moment a packet drops, cut back hard. Loss is the only feedback the sender trusts. That idea still runs on every device you’re holding right now.
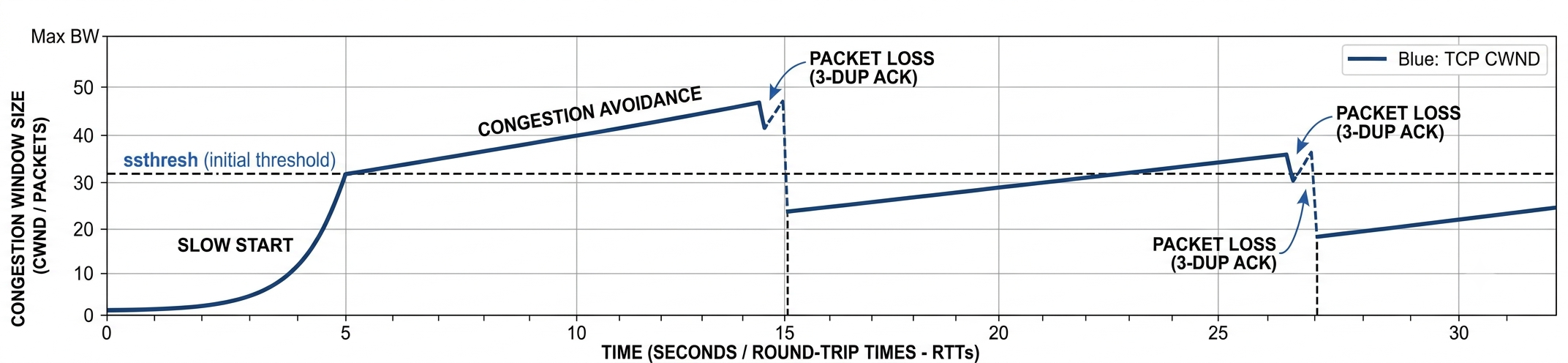
The Sawtooth
The classic algorithm has two modes. Both drive the congestion window or cwnd, which is how much data the sender keeps in flight. Slow start doubles the cwnd every round trip until congestion avoidance takes over[2]. Congestion avoidance then creeps forward, adding one packet’s worth per round trip. When a packet is lost, the sender halves cwnd and starts climbing again[1].
Additive increase, multiplicative decrease. Grow slow, cut deep. Plot the sending rate over time and you get a sawtooth, forever climbing toward the ceiling and getting knocked back down. That sawtooth is TCP Reno, and it worked for twenty years.
CUBIC Took Over
Reno’s flaw shows on long, fast links. On a 10-gigabit connection after a loss, additive increase adds one packet per round trip. A 100-millisecond round trip means roughly 40,000 round trips to refill the pipe, over an hour[3]. The bigger and faster the network grows, the worse the old approach performs.
CUBIC replaced the straight line with a curve. It tracks the time since the last loss and grows as a cubic function of it, rushing back toward the previous ceiling, flattening out as it gets close, then probing carefully past it[3]. It spread quickly and became the default across the internet.
CUBIC is faster and smarter, and it still uses the same loss-based model as Reno. A full buffer is the goal, which turns oversized buffers into a latency problem.
BBR Changed the Question
In 2016 a team at Google asked why loss should be the signal at all[4]. Their algorithm, BBR (bottleneck, bandwidth and round-trip propagation time) builds a small model of the path instead of reacting to packet loss. It measures the fastest rate the bottleneck can deliver and the lowest round-trip time it sees when the queue is empty, then paces packets to fill the pipe[4].
The bandwidth-delay product (bandwidth times RTT) is how much data it takes to fill a path. BBR aims to keep that much in flight, which keeps the bottleneck busy while leaving its buffer near empty. Low latency and high throughput at once, without waiting for a packet to drop. Google deployed BBR on its B4 wide-area network and measured 2 to 25 times higher throughput than CUBIC, with a peak of 133 times on one intercontinental path[4].
What Actually Ships Today
The early variants are mostly history. Tahoe added fast retransmit in 1988, so a sender no longer waits for a retransmission timeout to learn of a loss. Three duplicate ACKs from the receiver announce a gap and trigger a resend. Reno added fast recovery in 1990 so one loss halved cwnd instead of dropping the sender back to slow start, and NewReno refined that recovery to survive several losses at once[5]. When a kernel today says Reno, it means NewReno.
Linux defaulted to CUBIC since 2006[6]. BBR has been available as a loadable kernel module since 2016[4].
FreeBSD reached the same place a little later. NewReno held the default for years, until FreeBSD 14 switched to CUBIC in 2023[7]. On FreeBSD the algorithms are pluggable modules in a framework called mod_cc, alongside Vegas, HTCP, and DCTCP[8].
BBR and RACK are configured differently on FreeBSD, as alternate TCP stacks instead of congestion modules. RACK detects loss using SACK (selective ACK), which reports gaps and timing measurements instead of counting duplicate ACKs. Netflix wrote RACK and runs it across its OpenConnect CDN[9].
Windows and macOS both default to CUBIC[10]. Windows Server uses DCTCP for datacenter connections, but CUBIC for clients[11].
Neither BBR nor RACK are enabled by default. Loss-based, buffer-filling control still handles most internet traffic.
Where This Breaks Down
Loss-based control mistakes a full buffer for success. Reno and CUBIC ease off only when a packet drops, so they fill every queue to the brim before backing down. On today’s oversized buffers, that means high throughput bought with seconds of latency[3].
A drop doesn’t always mean congestion. Over wireless, packets get lost to interference more often than to a full queue. A loss-based sender reads that corruption as congestion and throttles itself for nothing, which is why a strong signal can still crawl[4].
A model can be unfair. BBR holds its own queue empty by design, but its first version could grab more than its share when it shared a link with loss-based flows, and later versions had to rework that coexistence[4].
No single algorithm fits every path. A datacenter with microsecond round trips wants nothing like what a flaky cellular link wants, which is why datacenters run their own congestion control built around explicit signals[12].
Put It Into Practice
Most people never touch this dial, and most never need to. The defaults keep getting better on their own.
If your servers stream bulk data over long or lossy paths, that’s different. Route a fraction of traffic to a canary running BBR, then watch two numbers against your CUBIC baseline, retransmit rate and p99 latency. Throughput alone won’t tell you enough. The gain tends to show up more in tail latency than in raw speed.
Check what’s active with sysctl net.ipv4.tcp_congestion_control, switch the canary with echo bbr | sudo tee /proc/sys/net/ipv4/tcp_congestion_control, and compare. If retransmits drop and tail latency improves while throughput holds steady or climbs, you’ve got evidence worth expanding the canary further.
Go Further
Congestion control for the datacenter. Inside a datacenter, round trips are microseconds and ordinary loss-based control is far too coarse. DCTCP uses explicit congestion marks instead of drops to keep queues a few packets deep[12].
A signal that isn’t a drop. The long arc of this field bends toward telling senders about congestion without throwing data away. L4S builds that explicit, low-latency signaling into the network itself[13].
References
- Jacobson, Van (1988). "Congestion Avoidance and Control." SIGCOMM '88. https://ee.lbl.gov/papers/congavoid.pdf
- Allman, Mark, Vern Paxson, and Ethan Blanton (2009). "TCP Congestion Control." RFC 5681. https://www.rfc-editor.org/rfc/rfc5681.html
- Ha, Sangtae, Injong Rhee, and Lisong Xu (2008). "CUBIC: A New TCP-Friendly High-Speed TCP Variant." ACM SIGOPS Operating Systems Review, 42(5). https://www.cs.princeton.edu/courses/archive/fall16/cos561/papers/Cubic08.pdf
- Cardwell, Neal, et al. (2016). "BBR: Congestion-Based Congestion Control." ACM Queue, 14(5). https://research.google/pubs/pub45646/
- Henderson, Tom, et al. (2012). "The NewReno Modification to TCP's Fast Recovery Algorithm." RFC 6582. https://www.rfc-editor.org/rfc/rfc6582.html
- The Linux Kernel (2024). "IP Sysctl: TCP Variables." Linux Kernel Documentation. https://docs.kernel.org/networking/ip-sysctl.html
- The FreeBSD Project (2023). "FreeBSD 14.0-RELEASE Release Notes." https://www.freebsd.org/releases/14.0R/relnotes/
- The FreeBSD Project (2024). "mod_cc: Modular Congestion Control." FreeBSD Kernel Interfaces Manual. https://man.freebsd.org/cgi/man.cgi?query=mod_cc&sektion=9
- The FreeBSD Project (2024). "tcp_rack: TCP RACK-TLP Loss Detection Algorithm." FreeBSD Kernel Interfaces Manual. https://man.freebsd.org/cgi/man.cgi?query=tcp_rack&sektion=4
- Iyengar, Janardhan, et al. (2024). "CUBIC for Fast and Long-Distance Networks." RFC 9438. https://www.rfc-editor.org/rfc/rfc9438.html
- Microsoft (2024). "Get-NetTCPSetting (NetTCPIP)." PowerShell Documentation. https://learn.microsoft.com/en-us/powershell/module/nettcpip/get-nettcpsetting
- Alizadeh, Mohammad, et al. (2010). "Data Center TCP (DCTCP)." SIGCOMM '10. https://people.csail.mit.edu/alizadeh/papers/dctcp-sigcomm10.pdf
- Briscoe, Bob, et al. (2023). "Low Latency, Low Loss, and Scalable Throughput (L4S) Internet Service: Architecture." RFC 9330. https://www.rfc-editor.org/rfc/rfc9330.html
Changelog
2026-07-03 Initial release.