 Image: Eppstein, David (2008). Public domain.
Image: Eppstein, David (2008). Public domain.
{kind=link}
Bloom Filter
Every time a Firefox user visits a TLS-protected website, the browser checks whether that site’s certificate has been revoked. A revoked certificate means the site’s identity can’t be trusted. The traditional approach queries the certificate authority (CA) on every connection, a network call that leaks which sites you visit and fails if the CA’s server is unreachable.
Mozilla ships a compressed representation of every revoked certificate on the internet directly to Firefox. On every HTTP/TLS connection, Firefox checks the certificate’s revocation status against the local copy. If the result is “definitely not revoked,” the connection proceeds. If the result is “might be revoked,” Firefox falls back to a live query. The fallback happens rarely.
The local data structure, called CRLite, was[10] implemented as a cascade of Bloom filters, each layer handling the false positives of the previous one.
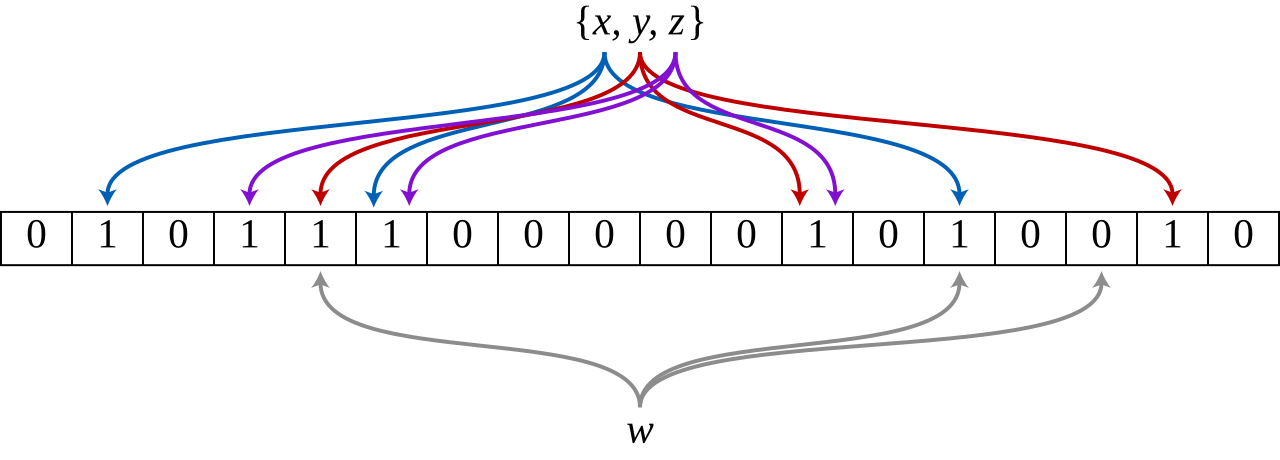
What a Bloom Filter Does
A Bloom filter is a probabilistic data structure for testing set membership. Burton Howard Bloom invented it in 1970 to check membership without storing the members[1].
The structure is a bit array, all initialized to zero. Adding an item means running it through k hash functions, each producing an index into the array, and setting those k bits to 1. Testing an item means running it through the same k hash functions and checking those k bits. If any bit is 0, the item is definitely not in the set. If all k bits are 1, the item is probably in the set.
Multiple items can hash to overlapping positions. When all of a tested item’s bits are already 1, those bits might have been set by other items. That’s a false positive. But false negatives are impossible. If an item was added, its bits were set, and the test always returns positive.
This asymmetry is the design. The filter guarantees absence but only approximates presence. Every use case depends on that guarantee.
Adding and testing both run in constant time. Each executes exactly k hash functions, regardless of set size.
A hash set of one million strings needs 50 to 100 megabytes. A Bloom filter for the same set needs a few megabytes[2], at the cost of occasional false positives.
Tune the False Positive Rate
The false positive rate depends on bit array size, hash function count, and items added[2].
At 10 bits per item, the false positive rate is around 1%. At 5 bits, it’s around 10%. At 15 bits, it drops below 0.1%. More space buys lower error. The calculator at hur.st/bloomfilter works backward from a target error rate and item count to the exact bit array size and hash function count.
Mozilla’s CRLite filter encodes the revocation status of nearly a billion certificates in a 4 megabyte snapshot shipped to Firefox every 45 days[9][10]. The fallback to a live query happens so rarely that users don’t notice.
Use the Bloom filter to rule out definite negatives. Invoke the expensive operation only for the remaining candidates. The space budget controls how many false candidates get through.
Where This Breaks Down
You can’t remove items. Setting bits to 1 is irreversible in a standard filter. Unsetting bits for a removed item could corrupt the signals for other items sharing those positions. Counting Bloom filters solve this by storing a counter per position instead of a single bit, using more memory.
The false positive rate rises as you add more items. The filter is designed for an expected maximum. Exceeding that fills the array and pushes the error rate above the design threshold. Set parameters for lifetime load, not current load.
You can’t retrieve members. The filter records whether items might be present, not the items themselves. There’s no way to enumerate what was added. To retrieve members, keep a separate data structure alongside the filter.
False positives aren’t safe without a fallback. Firefox’s CRLite works because a false positive triggers a live query, not a final decision. If the filter alone gates access to something security-critical, a false positive is an exploit. The structure requires a second gate.
Put It Into Practice
Use a Bloom filter when three conditions hold. The “no” case is common and expensive to verify, a false positive triggers a recoverable fallback, and the full set is too large to store.
Databases reach for them when most lookups return nothing. Apache Cassandra keeps a Bloom filter per SSTable (Sorted String Table)[4]. If the filter says “definitely not here,” Cassandra skips the data file entirely. One extra disk read in a hundred is acceptable. One per lookup is not.
Deduplication pipelines use them to avoid reprocessing items already handled. Recommendation systems use them to skip content users have already seen. Medium’s reading history per user is too large to query on every request, so a Bloom filter answers “definitely not read” in microseconds[5]. A false positive occasionally withholds an unread article. An acceptable miss rate for the savings.
Size the filter for maximum expected load. A filter designed for one million items at 1% error reaches 5% error when you load two million items. This isn’t adjustable after the fact. When a filter fills past its design threshold, rebuild it.
What This Doesn’t Cover
The probability math. The false positive rate isn’t an approximation. It’s exact. Broder and Mitzenmacher work through the full derivation. Given m bits, n items, and k hash functions, the rate is (1 - e^(-kn/m))^k, and the optimal k is (m/n) × ln(2)[2]. The numbers above come from that formula.
Estimating item count. Given how many bits are set to 1, you can estimate how many items were inserted without storing a separate counter. The formula follows from the same probability math. Given X bits currently set, n* ≈ -(m/k) × ln(1 - X/m)[2]. Useful for monitoring how close a filter is to its design threshold.
Cuckoo filters. A cuckoo filter achieves similar false positive rates with less memory and supports deletion natively[6]. Instead of a bit array, it stores short fingerprints in a hash table with two candidate buckets per item. Deleting an item means removing its fingerprint rather than unsetting shared bits.
Ribbon filters. A ribbon filter encodes set membership as a system of binary linear equations, approaching the theoretical minimum of log₂(1/ε) bits per item, roughly 30% smaller than a Bloom filter at the same false positive rate. The tradeoff is that construction requires solving the system in batch. Ribbon filters are static and don’t support incremental insertion.
Firefox replaced CRLite’s Bloom filters with ribbon filters in 2025[10]. CRLite was already built in batch from Certificate Transparency logs, so the static-only constraint wasn’t relevant. The 30% size reduction was. The filter ships to every Firefox user’s browser every 45 days. When the set is known upfront and space is tight, ribbon filters are the better choice. When items arrive incrementally and the full set isn’t known in advance, Bloom filters win.
The sketch family. Bloom filters belong to a family of probabilistic data structures. HyperLogLog estimates how many distinct items are in a stream[7]. Count-min sketch estimates how often each item appears[8]. Each makes a different tradeoff between memory and error.
References
- Bloom, Burton H. (1970). "Space/Time Trade-offs in Hash Coding with Allowable Errors." Communications of the ACM, 13(7): 422-426. https://dl.acm.org/doi/10.1145/362686.362692
- Broder, Andrei and Michael Mitzenmacher (2004). "Network Applications of Bloom Filters: A Survey." Internet Mathematics, 1(4): 485-509. https://www.eecs.harvard.edu/~michaelm/postscripts/im2005b.pdf
- Larisch, James, et al. (2017). "CRLite: A Scalable System for Pushing All TLS Revocations to All Browsers." IEEE Symposium on Security and Privacy 2017. https://obj.umiacs.umd.edu/papers_for_stories/crlite_oakland17.pdf
- Apache Cassandra (2024). "Bloom Filters." Apache Cassandra Documentation. https://cassandra.apache.org/doc/latest/cassandra/managing/operating/bloom_filters.html
- Talbot, Josh (2015). "What are Bloom filters?" Medium Engineering Blog. https://medium.com/blog/what-are-bloom-filters-1ec2a50c68ff
- Fan, Bin, Dave Andersen, Michael Kaminsky, and Michael Mitzenmacher (2014). "Cuckoo Filter: Practically Better Than Bloom." CoNEXT '14. https://www.cs.cmu.edu/~dga/papers/cuckoo-conext2014.pdf
- Flajolet, Philippe, Éric Fusy, Olivier Gandouet, and Frédéric Meunier (2007). "HyperLogLog: The Analysis of a Near-Optimal Cardinality Estimation Algorithm." AOFA '07. https://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
- Cormode, Graham and S. Muthukrishnan (2005). "An Improved Data Stream Summary: The Count-Min Sketch and Its Applications." Journal of Algorithms, 55(1): 58-75. https://doi.org/10.1016/j.jalgor.2003.12.001
- Larisch, James, et al. (2025). "Clubcards for the WebPKI: Smaller Certificate Revocation Tests in Theory and Practice." IACR ePrint 2025/610. https://eprint.iacr.org/2025/610
- Mozilla (2025). "CRLite: Fast, Private, and Comprehensive Certificate Revocation Checking in Firefox." Mozilla Hacks. https://hacks.mozilla.org/2025/08/crlite-fast-private-and-comprehensive-certificate-revocation-checking-in-firefox/
Outtakes
The one-hit wonder problem. Objects fetched exactly once and never again are called “one-hit wonders,” polluting the cache. Akamai fixed this with a Bloom filter, tracking first-time requests and promoting objects to the main cache only after a second fetch. Cache pollution dropped. (Maggs and Sitaraman, 2015)
Google Bigtable. Bigtable uses Bloom filters to skip disk reads for missing rows. Each SSTable can have a filter attached. A read for a missing key never reaches disk. The original paper calls out this optimization explicitly. (Chang et al., 2006)
Git. Since git 2.27, every git log -- <path> query runs against per-commit Bloom filters. Each commit in the commit graph stores a filter of which file paths it touched. Git skips commits that definitely didn’t change the path you’re querying. Most developers use it every day without knowing. (Singh, 2020)
Bitcoin SPV. Light wallets can’t download the full blockchain. They send a Bloom filter to full nodes, describing which transactions to return. The false positives are intentional. They add noise that hides which addresses the wallet actually owns. The error rate is the privacy mechanism. (BIP 37, 2012)
Changelog
2026-06-26 Initial draft.